Your cart is empty.
Tecan uses cookies to improve our website. By continuing to browse our website, you accept our cookie policy.
Tecan uses cookies to improve our website. By continuing to browse our website, you accept our cookie policy.









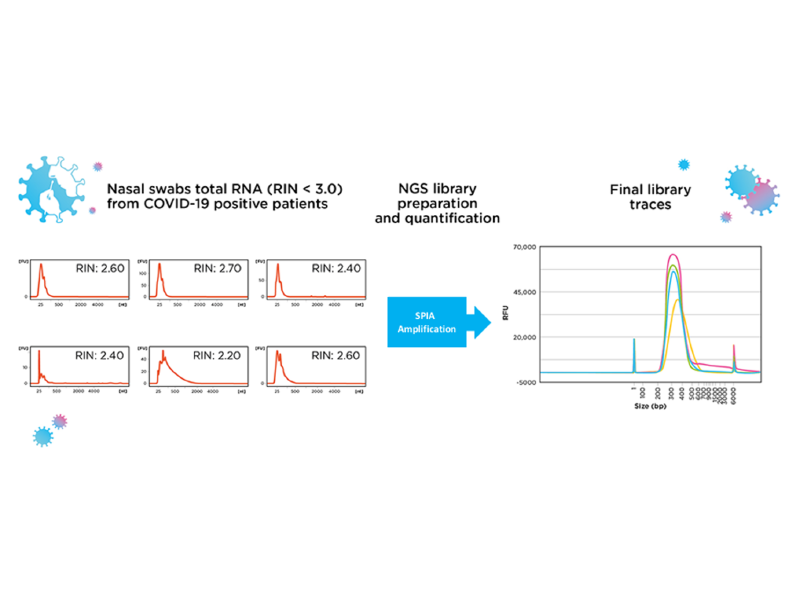
The figure demonstrates the performance of SPIA with a mix of low quality, degraded, and low concentration RNA.
As can be seen from the RNA traces, the quality of the RNA is very low (RIN<3).
Yet in each case the SPIA technology was used to amplify the sample creating a viable cDNA library.
Revelo RNA-seq library preparation solutions combine proprietary technologies to provide a streamlined solution for whole transcriptome RNA-seq from low-input or poor quality samples for rare transcript deletion and unbiased pathogen discovery.
Robust solution for enhanced qPCR detection from low input and degraded samples Quantitative PCR (qPCR) is a sensitive method that allows researchers to detect and quantify nucleic acids in a starting material.
Unique RNA-Seq library prep combines three proprietary technologies to provide a streamlined solution for whole transcriptome RNA-Seq library preparation from low input and poor quality samples for rare transcript detection and unbiased pathogen discovery.
Single Primer Isothermal Amplification (SPIA) technology provides industry leading whole transcriptome reverse transcription and cDNA amplification for low input and degraded RNA samples. The amplified cDNA can be used in a range of applications from NGS library prep and qPCR to sample archiving.
For years, the gold standard for library quantification has been qPCR – the only method with sufficient accuracy to ensure optimal flow cell loading. However, qPCR is a complex procedure that takes upwards of 90 minutes to get results. By contrast, NuQuant provides results in just 6 minutes, with qPCR levels of accuracy, and no dilutions, requiring only that the plate be read on any standard lab fluorimeter.

NuQuant is the only technology that can match the accuracy of qPCR, measuring only the sequenceable fragments and ignoring any other nucleic acids.
NuQuant is a proprietary method that does not require additional reagents or secondary library analysis methods, making it fast and simple.

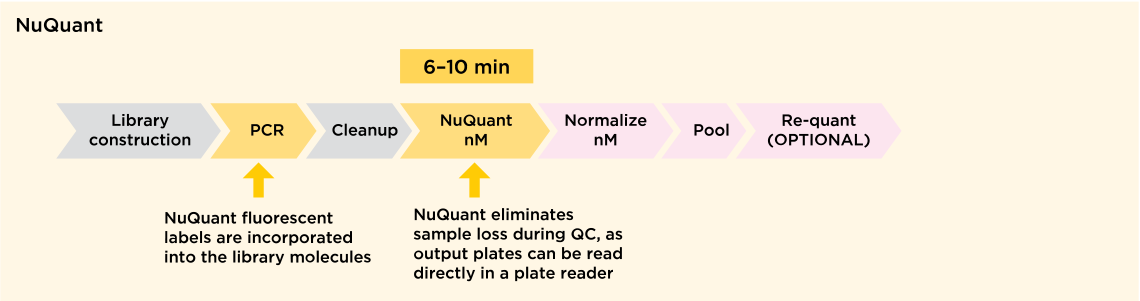
With NuQuant library quantification, a specific number of fluorescent labels are incorporated into the library molecules during library preparation.
As each library molecule has an equivalent number of labels incorporated, regardless of the size of the library fragment, the library molar concentration of 96 samples can be directly measured in less than 10 minutes using Infinite® or any standard plate reader. Alternatively, samples can be individually measured using Qubit® in around 6 minutes per sample.
Simple DNA-Seq library preparation kit that enables library construction in three steps. NuQuant library quantification technology included providing accurate library molarity in seconds.
Are you looking for a robust, time-saving DNA-Seq workflow? Celero EZ DNA-Seq Library preparation kit is a simple 3-step workflow integrated with NuQuant library quantification that provides a flexible solution for high-throughput DNA-Seq.
Revelo RNA-seq library preparation solutions combine proprietary technologies to provide a streamlined solution for whole transcriptome RNA-seq from low-input or poor quality samples for rare transcript deletion and unbiased pathogen discovery.
Streamlined solution for mRNA-Seq library preparation for sequencing on Illumina sequencers. This kit features a broad input range, UDI, and simple library quantification with NuQuant.
Streamlined solution for total RNA-Seq library preparation for sequencing on Illumina sequencers. This kit features broad input range, UDI adaptors, rRNA depletion with AnyDeplete and simple library quantification with NuQuant.
Streamlined solution for mRNA-Seq library preparation for sequencing on Illumina sequencers. This kit features a broad input range, UDI, and simple library quantification with NuQuant.
Streamlined solution for total RNA-Seq library preparation for sequencing on Illumina sequencers. This kit features broad input range, UDI adaptors, rRNA depletion with AnyDeplete and simple library quantification with NuQuant.
Robust solution for stranded whole transcriptome RNA-Seq library preparation for any sample type and RNA quality, integrated target depletion after library construction and library quantification.
Allegro provides a fast, scalable, cost-effective approach to perform targeted genotyping-by-sequencing with the ability to interrogate over 100,000 SNPs in a single assay on a wide variety of organisms using next generation sequencing.
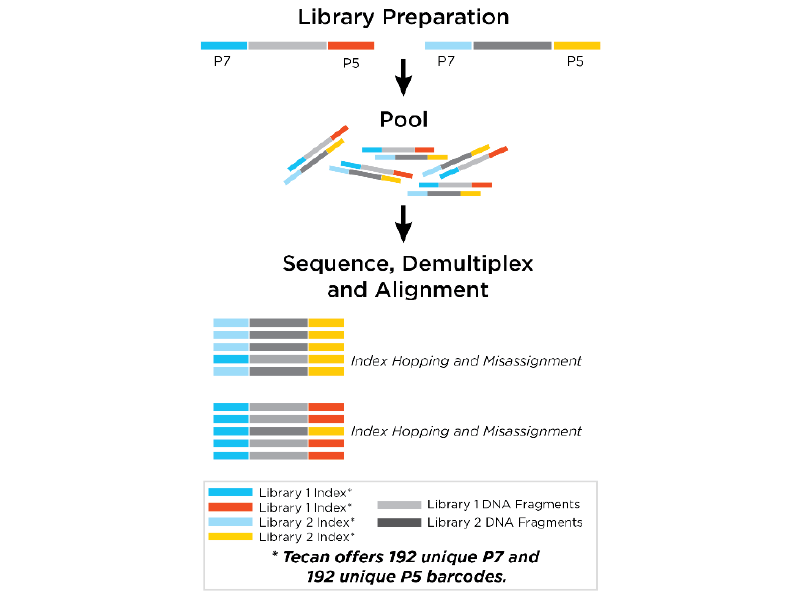
Tecan’s Unique Dual Indexes allow you to uniquely label up to 384 samples with a P7 and a P5 barcode, which are attached to the library fragments in a simple ligation step.
Ligation of two unique barcodes to each of the library fragments (one at each end) mean that the fragments are identified twice. This dual labeling is key to the detection of index hopping, a sequencing phenomenon that occurs at a low level with Illumina sequencing instruments and is most prevalent on patterned flow cells like those used by the Illumina NovaSeq.
If left unchecked index hopping can lead to mis-assignment of reads to the incorrect sample.
Using Tecan’s Unique Dual Indexes in library prep kits, enable the detection and elimination of mis-assigned reads from the sequence dataset.
Streamlined solution for mRNA-Seq library preparation for sequencing on Illumina sequencers. This kit features a broad input range, UDI, and simple library quantification with NuQuant.
Streamlined solution for total RNA-Seq library preparation for sequencing on Illumina sequencers. This kit features broad input range, UDI adaptors, rRNA depletion with AnyDeplete and simple library quantification with NuQuant.
Robust solution for stranded whole transcriptome RNA-Seq library preparation for any sample type and RNA quality, integrated target depletion after library construction and library quantification.
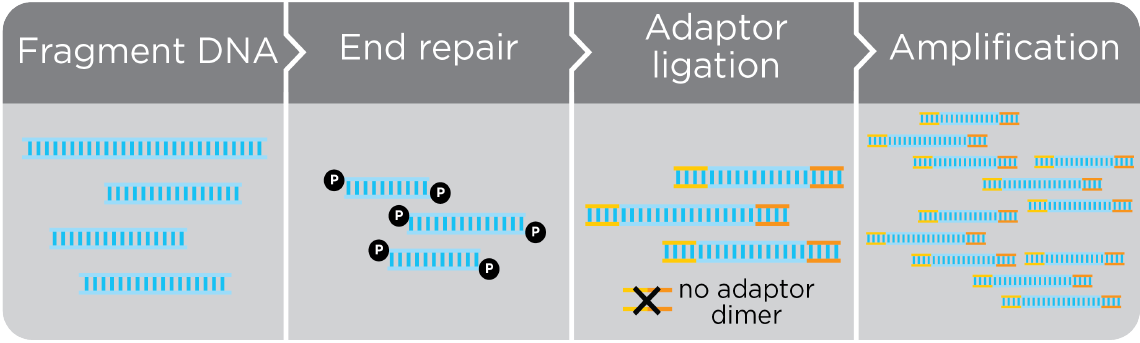
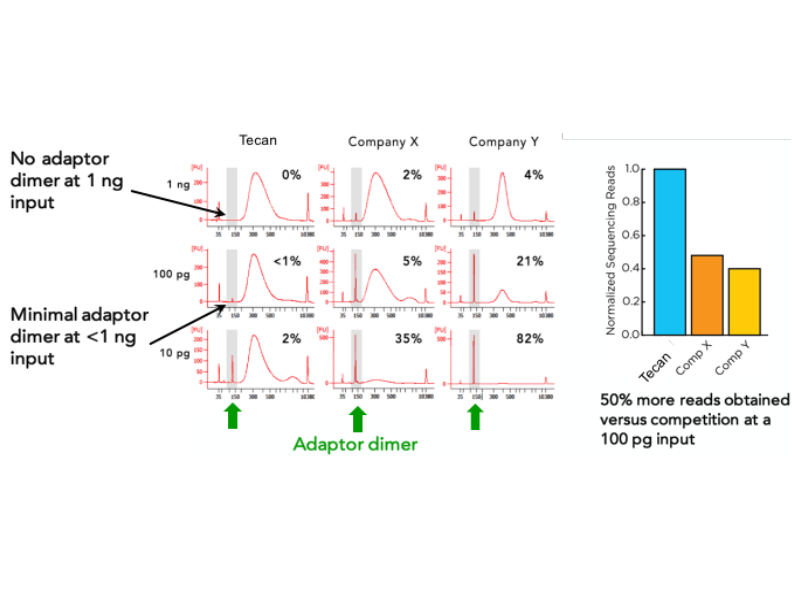
DimerFree works to eliminate adapter dimers immediately after adapter ligation and prior to amplification. Eliminating dimers from the pool of fragmented DNA prior to amplification means that only the adapter bound sample fragments go forward to amplification, and on to make up the final sequence ready library.
The power of DimerFree is clearly demonstrated in a head-to-head comparison of three different library prep kits.
At all concentrations Tecan with DimerFree produces a much cleaner library, this effect is especially noticeable as the concentration of the input DNA drops.
Simple DNA-Seq library preparation kit that enables library construction in three steps. NuQuant library quantification technology included providing accurate library molarity in seconds.
Are you looking for a robust, time-saving DNA-Seq workflow? Celero EZ DNA-Seq Library preparation kit is a simple 3-step workflow integrated with NuQuant library quantification that provides a flexible solution for high-throughput DNA-Seq.
Streamlined solution for mRNA-Seq library preparation for sequencing on Illumina sequencers. This kit features a broad input range, UDI, and simple library quantification with NuQuant.
Streamlined solution for total RNA-Seq library preparation for sequencing on Illumina sequencers. This kit features broad input range, UDI adaptors, rRNA depletion with AnyDeplete and simple library quantification with NuQuant.
Revelo RNA-Seq High Sensitivity library preparation solutions combine proprietary technologies to provide a streamlined solution for whole transcriptome RNA-seq from low-input or poor quality samples for rare transcript deletion and unbiased pathogen discovery.
The DNA-Seq Library Preparation Kit offering fast and scalable production of NGS libraries from degraded samples as low as 10 pg.